


Nonproliferation is the wrong approach to AI misuse
Making the most of “adaptation buffers” is a more realistic and less authoritarian strategy

I’m publishing 3 posts this week to celebrate the launch of Rising Tide—this is post #3. New posts will be more intermittent after this week. Subscribe to get them straight in your inbox:
There’s a common line of thinking in some AI safety circles that goes like this:
AI is becoming increasingly advanced, including in fields like coding and scientific R&D.
At some point, sufficiently advanced coding and R&D capabilities could make it much easier for bad actors to carry out massively harmful attacks, like hacking critical infrastructure or releasing novel bioweapons.
There are enough bad actors in the world (e.g. literal terrorist groups) that we can assume there will be attempted attacks.
We are not currently set up to reliably prevent such attacks, and even a single attack could be catastrophic (i.e. cause thousands or millions of deaths, perhaps even more).
The only way to manage this risk of catastrophic misuse is a hardcore nonproliferation strategy to prevent widespread access to these models.
Points #1-4 seem basically right to me. They describe one major reason to worry about what the world will look like if AI continues to advance rapidly (especially if it’s as insanely fast as the CEOs of top companies are predicting).
But I think #5—concluding that hardcore nonproliferation is the solution to the threat of AI misuse—is probably wrong. If such a regime were implemented seriously, it would be both ineffective and freedom-damaging. In this post I explain why and describe a resilience-focused alternative that I think is a better, even if not perfect, approach.
The idea that nonproliferation is the only way to deal with serious misuse risk is not new, but a recent paper from Dan Hendrycks, Eric Schmidt, and Alexandr Wang is an unusually clear articulation of it. They describe three pillars of a nonproliferation strategy: compute security (i.e. tracking the location of advanced chips to restrict their spread), information security (locking down access to the weights of misusable models), and AI safeguards (technical measures that reduce the chance that an AI model will help bad actors with attacks).

Notably, Hendrycks and co emphasize that this nonproliferation regime is not about maintaining a lead over other great powers in a race to build superintelligence, nor about easing the pressures for that to become a race to the bottom. A different section of their paper addresses those issues.1 Their three pillars of nonproliferation are purely about preventing malicious actors from accessing AI that could be catastrophically misused.
I’m not against these pillars per se—I’m open to them each having a place in a broader strategy to help AI go well (more below). And I agree that if the goal is to indefinitely prevent access to misusable models from spreading, you don’t have many options beyond these.
But that’s the wrong goal. Thinking primarily in terms of nonproliferation—especially on any timeframe longer than a couple of years—is the wrong approach to managing risks of AI misuse.
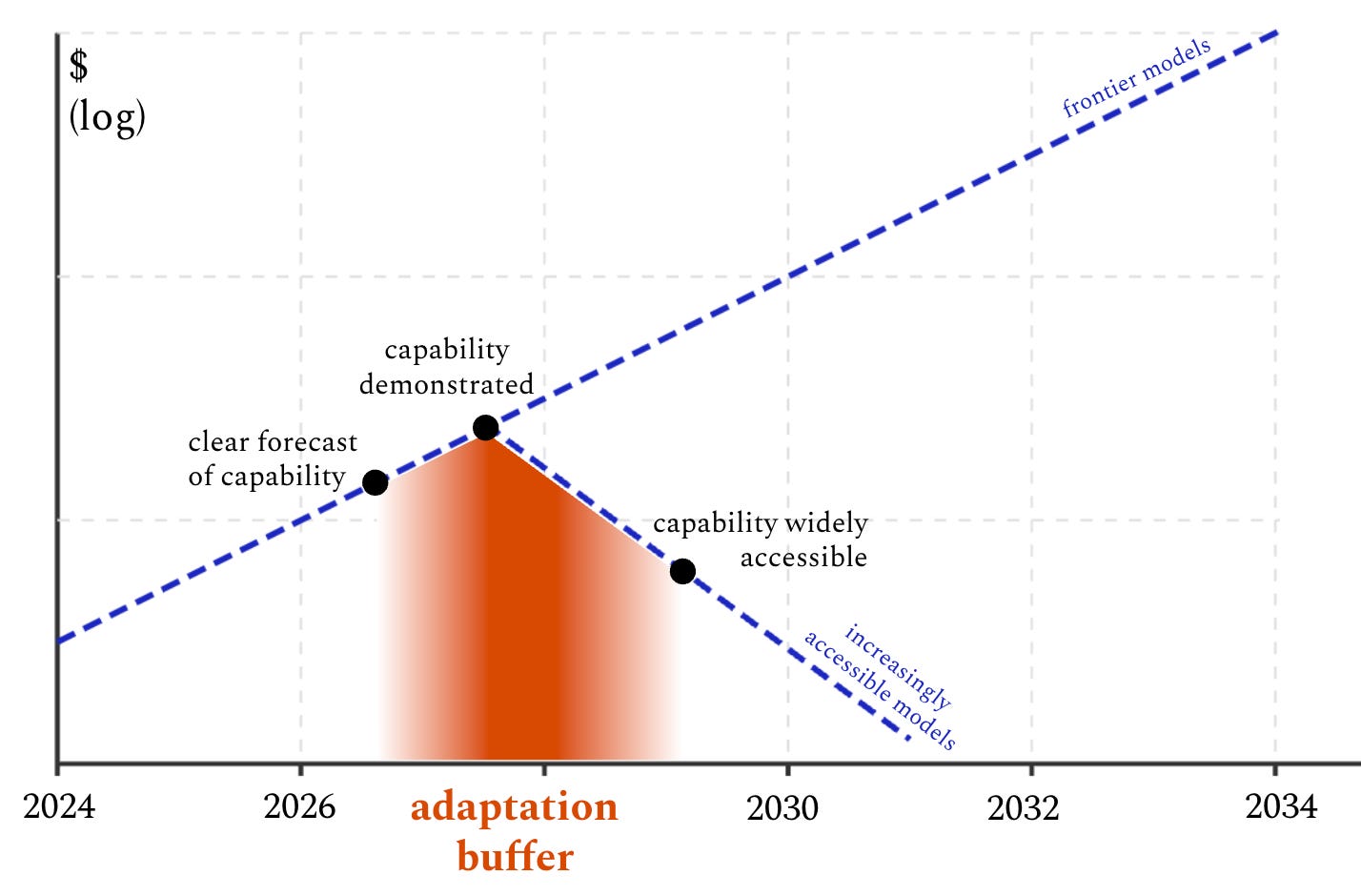
The reason why is the dynamic depicted in this chart. The dashed line going upward shows the steadily increasing cost (in terms of compute and other inputs) to train the very best model at any point in time. But the blue triangles depict an inverse dynamic that can be counterintuitive: once a certain level of performance is reached, the cost of replicating it falls dramatically over time.

This means there are two fundamentally different kinds of targets that policy can try to pursue: frontier targets and fixed-capability targets. If you’re targeting the frontier—say, because you want to know how rapidly we’re advancing towards AGI—then you can focus on those largest, most input-intensive, most compute-hungry systems. But if you’re worried about a fixed level of capability—say, the ability to help a novice hack the US power grid or engineer smallpox in their garage—then you’re in for a bad time. Even if that level of capability is extremely expensive when first developed, it will rapidly become cheaper and more widely available. Unfortunately, AI for bioweapons and hacking critical infrastructure fall into this second category—you need to restrict access to a certain fixed level of capability, not just the most advanced systems.2
The upshot is that AI nonproliferation (to counter terrorist misuse) works quite differently from nuclear nonproliferation (to counter nuclear weapons development). Imagine a world where advances in nuclear technology mean that the amount of uranium and level of enrichment needed to make a tactical nuke keeps dropping. At first, it would be relatively simple to track and restrict access to large quantities of uranium and advanced enrichment facilities. But eventually, anyone with a large enough plot of land would be under scrutiny, due to the tiny amount of uranium naturally present in soil. A nonproliferation regime would have to become more and more invasive—and less and less effective—as the number of actors, events, and materials to track ballooned. Fortunately, the technology to create nuclear weapons has not progressed in this way. But with AI, it’s different: it’s often only a couple of years between when you need a world-class computing cluster to do something and when you can run it on a high-end gaming chip on your laptop.
Many AI nonproliferation opponents (aka the open source community) seem to think the argument can stop here: Trying to prevent the spread of AI that could be catastrophically misused would be draconian and wouldn’t even work, so we shouldn’t do it.
But that doesn’t help at all with the underlying problem! If we’re on track to build AI that can be catastrophically misused, we need other solutions.
Adaptation buffers: an opportunity for defensive measures & building resilience
Here’s what I think the realistic alternative is: We should think of the gap between frontier models and proliferated models as an adaptation buffer: a limited time window when we know what bad actors will soon be able to use AI for, which gives us a chance to implement defensive measures that increase society’s resilience to the danger.
Discussions of how to manage misuse risks from AI with advanced biosecurity or cyberoffense capabilities often focus on "offense-defense balance," or how much the AI advances that create new risks of attack also create new ways to defend. To the extent that not-yet-proliferated frontier AI systems can be used to implement defensive measures—e.g. in AI-based cyberdefense or AI-assisted disease monitoring—that’s great, and should be part of the adaptation buffer strategy. But making use of the adaptation buffer can be much broader than “using good AI to defeat bad AI.” The full suite of defensive measures available includes many things that do not necessarily involve AI.
On cybersecurity, making use of the adaptation buffer could include things like:
Kicking off a massive capacity-building initiative to educate critical infrastructure providers about the AI-driven cyber threats they are likely to face in the near future, and support them in reworking their cybersecurity practices accordingly.
Incentivizing the development of new cyberdefense tools using the best AI models available, with the goal of ensuring that new cyber capabilities in frontier models are integrated into broadly deployed defensive software before they become widely available for offensive use.3
Creating plans for economy-wide crisis response and recovery in the aftermath of major AI-driven cyberattacks.
And for biosecurity, things like:4
Ramping up measures to monitor and screen access to key services and materials, along the lines of the DNA synthesis screening rules included in Biden’s AI executive order.
Investing in medical countermeasures for pandemics, especially to a) advance more pathogen-agnostic approaches like a universal flu vaccine or broad-spectrum antivirals and b) build infrastructure that allows rapid scaling of vaccines or treatments as needed.
Stockpiling personal protective equipment (PPE) to allow rapid distribution in the event of an outbreak.
Scaling up disease detection and monitoring infrastructure to enable faster and more effective response to outbreaks.
These are not actually the right recommendations, because I am not an expert in either cybersecurity or biosecurity. But I hope they are a helpful sketch of the kind of thing I mean: large-scale, multi-faceted efforts to bolster broad societal resilience, in preparation for new dangerous capabilities that we anticipate will soon be widespread.
Per the rough diagram above, there are two ways to increase the size of the adaptation buffer for a given capability, both of which I think are worthwhile:
Limited, targeted nonproliferation efforts to push back the date when a capability will be widely available. The current status quo—where new models that push the frontier are kept private, and openly available equivalents are only released after a lag of months or years—is valuable. To the extent that this kind of precautionary friction counts as “nonproliferation,” I’m in favor.
Work that improves our ability to clearly forecast specific concerning capabilities that will be developed soon. For example, it’s very good that leading AI companies have started running uplift trials to test how much their models aid humans in making bioweapons. It looks to me like we’ve already reached the “clear forecast of capability” point for models that can help novice humans to create known pathogens, which means we’ve already entered the adaptation buffer for that capability and should start working on mitigations.5
Ifs and Buts
If AI advances are very fast, this might not be enough to avoid catastrophe
My argument in this post is that focusing on making the most of adaptation buffers is a better strategy to manage the threat of AI misuse than focusing on indefinite nonproliferation. That does not mean that it’s a strategy that will definitely work. If we end up in a world where AI is advancing very quickly—perhaps a world where we have to deal with multiple novel misuse threats at once, plus some combination of major economic disruption, major geopolitical turmoil, and the possibility of losing control of superintelligent AI systems, all within the span of less than a few years—then I don’t particularly like our chances.
Even if we are only dealing with one type of threat at a time, it’s possible the adaptation buffer we get will be so short, or the necessary adaptations so hard to implement, that AI-aided attacks cause huge damage. Perhaps techniques are developed that suddenly make already-proliferated models much more capable hackers. Perhaps it turns out to be extremely difficult to overhaul the cybersecurity practices of critical infrastructure providers. If we get unlucky with factors like these, we may not be able to avoid catastrophic attacks.
Nonetheless, I still think maximizing how much adaptation juice we can squeeze out of the buffers we do get is a better focus than clamping down on access.
None of this is about tracking the frontier—or about the risk of AI takeover
Above, I introduced the idea of “frontier targets” and “fixed-capability targets.” The argument in this post does not apply to anything related to frontier targets.
In fact, several of Hendrycks and co’s recommendations strike me as promising, if they are used in a way that focuses on frontier targets rather than fixed-capability targets. Semiconductor export controls, for instance, are useless if the goal is to prevent anyone from stacking 8 GPUs in their basement. But they’re much more realistic if the goal is to reduce how many players can build the world-class computing clusters currently required to train frontier models, which may contain hundreds of thousands of leading-edge AI chips. Likewise, I’m pessimistic about the firmware-level features they suggest as a way to tackle terrorist misuse, but these seem potentially promising (with much more underlying technical work needed!) as a mechanism for verifying US-China agreements on advanced AI.6
This post is also not about risks from AI models themselves, also called “loss of control” or “takeover” risks. As a species, we have a lot of experience with new technologies putting increasingly powerful tools into bad actors’ hands (“misuse”). I see adaptation buffers as a variation on the usual way we deal with this kind of threat, by adapting over time. But we do not have experience with the kinds of problems we’ll face if we build machines that are smarter and more capable than us, so I feel much less sanguine that an adaptation-based strategy will help us there.
This might not be that different from what many AI nonproliferation advocates mean, if they explained themselves better
Usually when I hear people advocating for AI nonproliferation, two things are true: 1) they motivate it in terms of misuse risks, and 2) they imply that we need to prevent proliferation indefinitely. Hendrycks and co make both 1) and 2) very explicit, so it seems they really do mean that version. But with other people in the space, I often find that if I push a little, the version of nonproliferation they have in their head turns out to be different: they are at least as worried about AI takeover as they are about AI misuse, and they think that AI progress will be so fast that nonproliferation would only apply for a short time anyway. The actual interventions they think will help are things like delaying open releases of new capabilities by a year or two, preventing China from stealing U.S. frontier models, and giving defenders time to adapt before attackers get access to new capabilities.
As I wrote immediately above, this isn’t so different from my view! But it’s really quite a different mindset from AI nonproliferation as it’s usually publicly presented, and the discrepancy leads to bitter debates and serious misunderstandings. I suspect a dynamic that's often at play is that nonproliferation advocates worry that very fast AI progress and the risk of AI takeover both sound wacky, whereas wanting to stop hackers and bioterrorists sounds more respectable. But then they either don’t realize or don’t care that for onlookers, they seem to be arguing for a long-term, anti-misuse-focused nonproliferation regime that will probably be both ineffective and highly invasive. By trying to use misuse as a fig leaf for their real concerns, they end up sounding much less credible than if they just tried to argue for what they actually meant.
I hope this post offers some language that can help make these different ideas clearer. Some members of the AI safety coalition have in fact argued for totalitarian surveillance as a long-term solution to technological risks, so if that's not what you mean, don't imply it. Delaying proliferation a little bit to stretch out our adaptation buffer—and then pushing as hard as we can to make the most of that buffer—is a very different thing.
To make sure it’s clear: if I've written this in a way that makes it sound like we can all relax, it'll be fine, we have plenty of time… then I've done it wrong. That is not at all my view. On the contrary, making the most of the adaptation buffer for any given misuse threat will require multiple ambitious, large-scale projects with a real sense of urgency. Note also, though, how focusing on adaptation and resilience calls our attention to the wide range of actions by a wide range of actors that could be helpful. On the one hand, this is sobering: we have a ton of work to do. On the other, it can be a source of optimism: managing AI misuse doesn’t all come down to whether we can pull off a massive feat of international coordination to set up and enforce a nonproliferation regime. Instead, there are tons of productive things that can be done by state and local governments, startups and established companies, individuals and organizations. We should get moving.
Thanks for being an early reader of Rising Tide! This concludes the set of 3 posts published this week to celebrate the launch of this substack. Going forward, I’ll post more intermittently - hopefully every few weeks or so. To make sure you see future posts, subscribe now:
Their suggested approach for managing the risks of a race to superintelligence is a mutual assured AI malfunction (MAIM) deterrence regime, which is the main contribution of their paper. This post is not about MAIM.
I’ve heard people argue that the frontier is actually the relevant thing here, because you can use frontier models to defend against anything less advanced (e.g. you could GPT-6-level cyberdefense to defend against GPT-5-level hacks, or Claude 5’s biomedical knowledge to develop vaccines against Claude 4-level engineered viruses). I think this can work to some extent in some cases, but it makes more sense to consider it as one element of the strategy I’m arguing for—adaptation buffers—rather than as a reason to aim for nonproliferation overall. I go into more detail on this later in the post.
More generally, we should be building out AI-based products and workflows that (a) contribute to societal resilience and (b) are designed to make the most of continuing advances in AI.
Credit to Batalis 2024 for inspiration on several of these (but any errors are mine!)
For example, OpenAI’s system card for Deep Research states: “Several of our biology evaluations indicate our models are on the cusp of being able to meaningfully help novices create known biological threats”
There’s some interesting early work on flexible hardware-enabled guarantees, aiming to implement the kinds of features mentioned in the Hendrycks paper in a privacy preserving way. I’m not deep enough on it to have a real take other than being intrigued.
Well said. I've been arguing almost exactly this internally! Delaying proliferation is one thing; forecasting (inc. using frontier for empirics) and mobilising resilience is another. I've also emphasised that 'automation isn't automatic', so using frontier to defend against trailing isn't a free lunch: prep pays dividends (related to your footnote 2).
This is a great policy post - one of the best I've read in the space.
I hope you get more traction on this, since state capacity seems to be exclusively pointed at the race dynamic itself.